How Attention Works: Real-Life Analogies Comparing Transformers and LSTMs
Setting the Stage: From LSTMs to Transformers
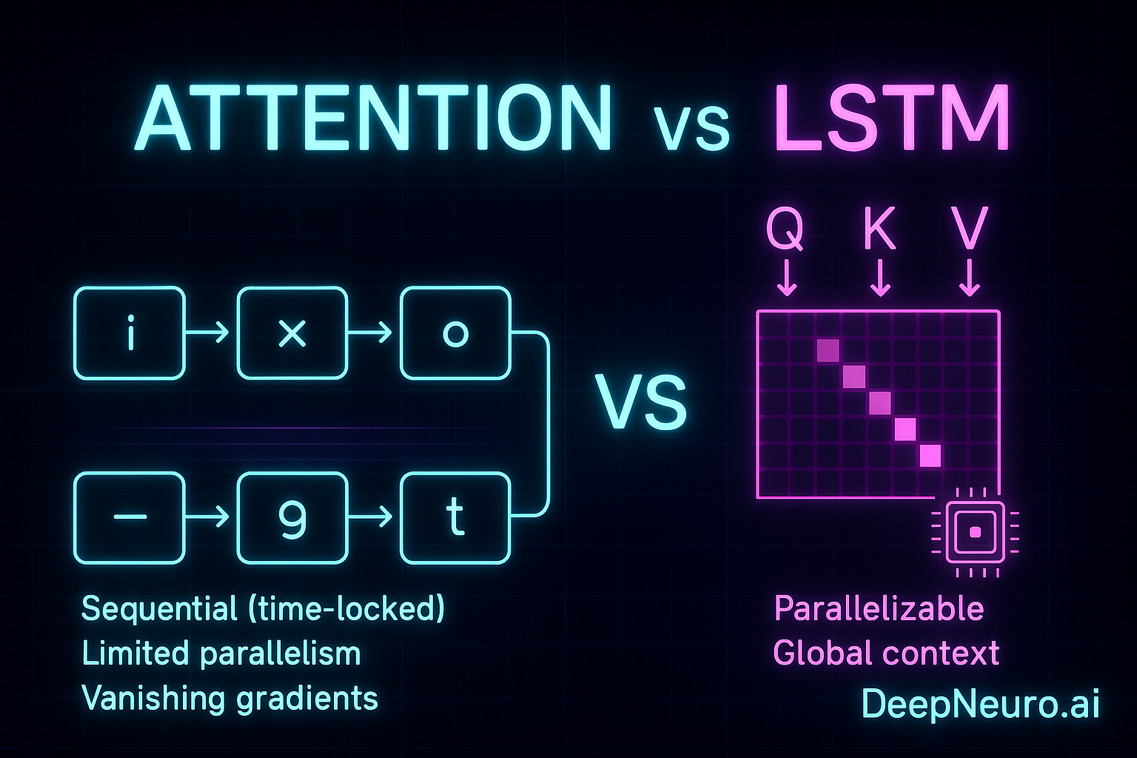
When researchers introduced sequence models like the long‑short‑term memory (LSTM), they were responding to the problem that recurrent neural networks had trouble remembering things from far in the past. LSTMs introduced a gating mechanism that let the model decide what to forget and what to retain. For years this was considered state‑of‑the‑art. However, by 2017 Google’s “Attention Is All You Need” paper argued that we could throw away recurrence altogether and still build powerful sequence models.
A Transformer uses attention to examine every part of the input at once. Instead of stepping through a sentence word by word, it looks at the whole sentence and figures out which words matter most for predicting the next one. This ability to directly connect distant words means a model can learn long‑range relationships more efficiently, and the architecture lends itself well to parallel computation.
What Does “Attention” Mean? A Human Analogy
Imagine you’re reading a long novel. Your friend asks you, “What was the author hinting at in the first chapter?” If you were an LSTM, you would have to mentally replay each page in the order you read them, because your memory stores information sequentially. By the time you reached chapter ten you might have forgotten the details of chapter one.
Attention works differently. Think of it like using sticky notes to mark important paragraphs. When you need to answer your friend, you don’t reread every page; you flip directly to the sticky notes and focus on the highlighted sections. In technical terms, attention assigns a weight to each word or sentence based on how relevant it is to the task. The model then builds its understanding primarily from the most relevant pieces.
Another analogy is having a conversation at a noisy party. An LSTM is like someone who listens to each conversation linearly, trying to remember everything that was said. It can keep track of the last few sentences but may lose track of the first ones. An attention‑based model acts like a seasoned host who surveys the entire room. When someone calls their name from across the room, the host can focus on that voice and tune out the rest, no matter how long ago or far away the voice originated.
Why the Change Matters
LSTMs were groundbreaking because they introduced a way to retain information over longer sequences than basic recurrent networks. They are still widely used in smaller systems and settings where data streams in one piece at a time. However, they process sequences in order, which makes it hard to parallelise training and limits their ability to handle very long contexts.
Transformers, by relying solely on attention, avoid these bottlenecks. Because every word can attend to every other word, the model has a global view and can decide which parts of the input are most relevant. The original Transformer research showed that this approach could handle long‑distance relationships better and train more efficiently.
From a real‑life perspective, think about learning a new language. LSTM‑like learning is akin to memorising phrases one at a time. It works, but you might struggle to remember phrases you learned months ago. Transformer‑style learning is more like immersing yourself in conversations and picking up context clues from multiple parts of the discussion simultaneously. You not only remember more distant phrases but also build a holistic picture of how the language works.
Attention in Older Models vs. Transformers
Before Transformers, attention was sometimes bolted onto LSTM‑style models to help them focus on certain parts of the sequence. For example, in machine translation systems, an encoder LSTM read a sentence in the source language and a decoder LSTM generated the translation. Adding an attention layer allowed the decoder to “peek” back at specific encoder states instead of relying solely on the last hidden state. This improved translation quality because the model could focus on the relevant source words when generating each target word.
Transformers took this idea to its logical extreme. By removing recurrence entirely and using multi‑head attention, they compute attention in parallel across multiple representation subspaces. In our party analogy, this is like having several hosts listening for different types of conversations—one paying attention to names, another to topics, and another to emotions. Each host brings their own summary of what matters, and the combined view leads to a richer understanding.
Respecting the Past, Looking Ahead
It’s easy to get caught up in the hype and dismiss older models outright. That would be a mistake. LSTMs and other recurrent networks solved genuine problems and still power many real‑time applications today, such as speech recognition in resource‑constrained settings. They represent an important stepping‑stone in the evolution of sequence modelling.
At the same time, the success of attention‑based models can’t be ignored. Their ability to scale and to capture long‑range dependencies has enabled the current wave of large language models. For those curious about how AI works under the hood, understanding the transition from LSTMs to Transformers is like seeing how a craftsman’s tools have evolved. We still use hammers and saws, but sometimes a power tool is more efficient.
In the next decade, researchers will likely continue refining attention mechanisms and exploring hybrids that bring back the best ideas from recurrent models. As in any field, progress builds on the past rather than discarding it.
Draft saved. Let me know if you want to tweak or expand any sections.



