Demystifying Model Quantization: Why Less Precision Can Be Enough

I love Quantization, you can see some of the models I have Quantization on my Ollama or Huggingface profile.
What Is Quantization?
In machine learning, quantization is a technique that reduces the computational and memory costs of running a model by lowering the precision of its numbers. Instead of storing every weight and activation as a 32‑bit floating‑point number, you can represent them with lower‑precision data types like 8‑bit integers or floating points (Quantization). This reduces the size of the model and allows it to run faster and more efficiently on hardware such as GPUs and mobile devices (What is Quantization? | IBM, Quantization in Deep Learning).
Quantization isn’t magic (well maybe it is) you’re literally chopping off some bits, which means the numbers are less precise. However, with careful calibration and training techniques, the impact on accuracy can be minimal. That makes quantization attractive when resources are limited or when you want to deploy models on the edge.
The GPS Analogy
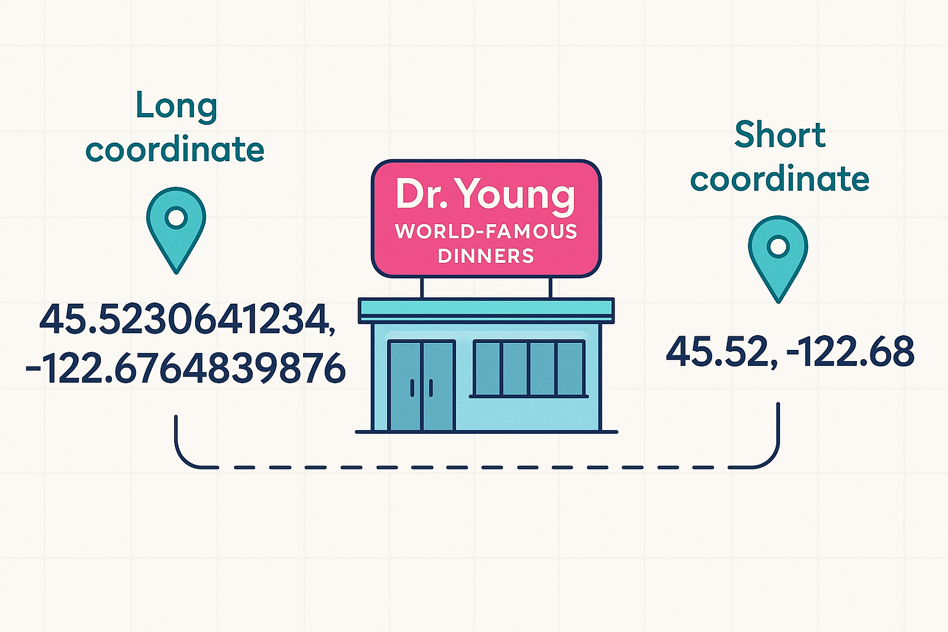
Think about how you might share your location with a friend. A GPS receiver can provide latitude and longitude with many digits of precision. If you give someone ten or fifteen decimal places, they could find the exact brick you’re standing on. But in most cases that level of detail is unnecessary. If you want to direct a friend to a particular McDonald’s, you don’t need to share the precise millimetre coordinates; rounding off the last few digits is enough for them to arrive at the right restaurant.
Quantization in neural networks works the same way. The exact weight values in a model are like long GPS coordinates: full of detail, but that detail isn’t always needed to get to the right answer. By trimming the number of bits used to store each weight, we keep the essential information and discard the tiny variations that don’t affect the end result. The model still “finds the McDonald’s,” but it does so using less memory and compute.
How Quantization Works
Most deep‑learning models are trained in high precision, using 32‑bit floating‑point numbers for weights and activations. Quantization converts these values to lower‑precision formats. Two common approaches are:
- Post‑training quantization: After the model is trained, the weights are converted to lower precision. This method is straightforward but may cause a small drop in accuracy if the model isn’t calibrated.
- Quantization‑aware training: The model is trained with quantization in mind from the start. During training, weights and activations are simulated at lower precision, allowing the model to adapt to the reduced precision and maintain accuracy.
Lower‑precision formats include int8 (8‑bit integer), FP16/BF16 (16‑bit floating points) and increasingly FP8 or even 4‑bit numbers. Each step down cuts memory and computational needs roughly in half, although at some point the loss of precision will hurt performance. Researchers are experimenting with which layers and operations can be quantized safely and how to mix different precisions.
Why Quantization Matters
As models have grown larger, the cost of running them has exploded. Quantization addresses this by reducing the size of the model and the number of operations needed to compute outputs. For example, representing weights as 8‑bit integers instead of 32‑bit floats can reduce model size by roughly 75 % (What is Quantization? | IBM). That translates to faster inference, lower latency and reduced energy consumption. It also enables models to run on devices with limited memory, such as smartphones or embedded systems.
The trade‑off is accuracy. In some cases, dropping precision will cause a slight decrease in model quality. But many tasks tolerate a little noise, and techniques like quantization‑aware training help close the gap.
Looking Ahead
Recently, there has been excitement around newer low‑precision formats like FP8. Projects such as DeepSeek’s research suggest that training models with 8‑bit floating points can achieve performance comparable to BF16 while doubling throughput. There are also mixed‑precision strategies where sensitive layers remain in higher precision while others are quantized aggressively. I’ll explore these developments in a future post.
For now, remember the GPS analogy: when you’re guiding someone to a destination, sometimes fewer digits are all you need. Quantization applies the same principle to machine learning models, trimming excess precision to make them lighter and faster without losing their way.
Draft saved. Let me know if you’d like to adjust or expand any sections.



